图数据库作为一种专门用于存储和处理图结构数据的数据库,在处理复杂关系、社交网络、推荐系统、欺诈检测等领域展现出巨大优势。在开源图数据库领域,TitanDB及其继任者JanusGraph是重要的技术选择。本文将系统性地介绍其入门知识、实战、选型对比,并深入分析其存储结构与数据处理服务。
一、入门简介:从TitanDB到JanusGraph
TitanDB 是一款早期开源的分布式图数据库,支持处理超大规模的图和并发事务。其核心特性包括支持Gremlin图遍历语言、分布式架构、以及可插拔的后端存储(如Cassandra, HBase)与索引引擎(如Elasticsearch, Solr)。随着开发逐渐停滞,其社区分支演化为 JanusGraph。
JanusGraph 继承了TitanDB的核心代码与架构,并在Linux基金会的支持下持续发展。它增强了分布式图计算的扩展性、完善了社区生态,并提供了更活跃的维护。对于新项目,通常建议直接采用JanusGraph作为技术选型。
入门JanusGraph,首先需理解其核心组件:图实例(Graph)、图遍历源(GraphTraversalSource)以及Gremlin查询语言。一个简单的本地部署可能涉及配置一个后端存储(如BerkeleyDB用于测试)并启动Gremlin Server。
二、实战关键步骤与常见模式
- 环境搭建与配置:生产环境通常选择分布式后端,如Cassandra或HBase作为存储层,Elasticsearch作为索引层。配置文件的优化(如缓存设置、连接池)对性能至关重要。
- 数据建模:图数据库建模的核心是顶点(Vertex)、边(Edge)和属性(Property)。需要仔细设计顶点标签、边标签及属性键,考虑查询模式,避免超级节点问题。
- 数据导入:批量导入推荐使用
GraphOfTheGodsFactory类似的工具或编写Gremlin脚本进行批量处理,注意在导入过程中合理使用事务和批量提交以提高效率。 - 查询与遍历:熟练掌握Gremlin语法是关键。例如,查找某人的朋友的朋友:
g.V().has('name','Alice').out('friend').out('friend').values('name')。应利用索引加速属性查找,避免全图扫描。 - 运维与监控:监控后端存储(Cassandra/HBase)的性能指标、JanusGraph自身的指标(如缓存命中率),并定期进行数据备份与图分析(如计算度中心性)。
三、选型对比:JanusGraph vs. 其他图数据库
- 与Neo4j对比:Neo4j是单机主从架构的领先者,拥有极佳的成熟度、友好工具和查询性能(Cypher语言)。JanusGraph强在分布式扩展性,能处理超大规模图,但运维复杂度更高。选择取决于数据规模与团队技术栈。
- 与Neptune(AWS托管服务)对比:Neptune是基于Titan/JanusGraph思想的云托管服务,简化了运维但锁定云厂商。JanusGraph提供更灵活的自托管与多云部署能力。
- 与Dgraph对比:Dgraph是原生分布式图数据库,使用GraphQL±查询语言,在分布式事务和查询性能上有独特设计。JanusGraph生态更成熟(兼容TinkerPop栈),社区工具更多。
选型建议:若需处理千亿级顶点/边且团队有分布式系统运维能力,JanusGraph是强大选择。若数据量在百亿级以下且追求开发效率,Neo4j可能更合适。云原生场景可评估Neptune。
四、存储结构深入分析
JanusGraph的存储结构是其分布式能力的基石,采用“邻接表”的变体进行存储。
- 数据布局:
- 顶点及其属性:以顶点ID为键,序列化存储所有属性。
- 邻接关系(边):边被存储在起始顶点的序列化数据中,包含边ID、指向的顶点ID、边标签和边属性。这种设计使得遍历顶点的出边极其高效(一次读取)。
- 索引数据:为支持按属性快速查找顶点,属性索引被单独存储在后端(如Elasticsearch)或作为辅助表/列族存储。
- ID分配与分区:JanusGraph支持自定义顶点ID,或使用其分布式ID分配器(基于后端存储如Cassandra的轻量级事务)生成唯一、可分区ID。合理的分区策略(如按顶点ID范围)对负载均衡至关重要。
- 序列化与存储格式:数据在写入前被序列化为紧凑格式。存储后端(如Cassandra)的列族设计直接影响读写性能。例如,一个顶点的所有数据可能存储在Cassandra的一个行键下,其邻接边作为列存储。
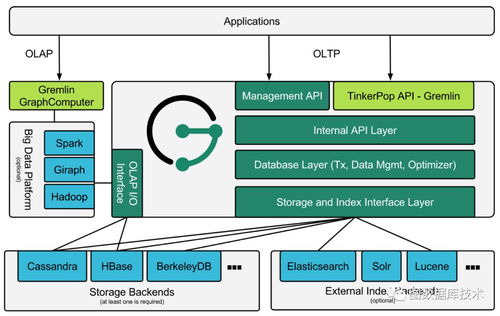
五、数据处理与存储服务架构
JanusGraph的架构清晰地将数据处理层与底层存储服务解耦。
- 数据处理层(JanusGraph Core):
- 事务管理:提供ACID语义的事务,支持多线程并发。事务缓存(Transaction Cache)和数据库级缓存(Database-Level Cache)用于提升性能。
- 查询处理与优化:Gremlin查询被解析、优化为一系列基础操作。优化器会尝试利用索引、调整遍历步骤顺序。
- 图元素序列化:负责将顶点、边等对象与底层存储格式相互转换。
- 存储服务层(可插拔后端):
- 存储后端:如Cassandra、HBase、Bigtable等,负责持久化图数据(邻接表)和事务日志。它们提供了最终的数据分布、复制与容错能力。
- 索引后端:如Elasticsearch、Solr或Lucene,专门处理属性索引,支持全文搜索、范围查询等复杂条件过滤,极大加速特定查询。
- 协同工作流:一次查询可能涉及:查询解析 -> 检查是否可利用索引(通过索引后端) -> 获取顶点ID -> 从存储后端读取顶点及邻接边数据 -> 在内存中执行遍历逻辑 -> 返回结果。
****:JanusGraph作为一款企业级分布式图数据库,通过其灵活的存储后端架构、强大的Gremlin查询能力以及对大规模数据的支持,在复杂关系数据管理领域占据一席之地。深入理解其存储原理与架构设计,是进行高效数据建模、性能调优和稳定运维的关键。尽管学习和运维成本相对较高,但其带来的处理超大规模关联数据的能力,使其在特定场景下成为不可替代的解决方案。